Computer vision is a rapidly developing area of AI. To facilitate data scientists to build different model architectures, some institutions are very generous to share the image dataset. In this article, 10 commonly used dataset will be introduced.
1. The Modified National Institute of Standards and Technology database of handwritten digits (MNIST database, in short)
It is the elementary dataset for computer vision. It consists of 70thousands images of hand-written digits for each number, i.e. 0–9 which are formatted in 28x28 grayscale. The data is prepared by Professor Yann LeCun. The data is pre-split into a training set (60thousands) and a test set (10thousands) in the release. All digits are placed at the centre in the image. It is used for a fundamental computer vision project, hand-written digital recognition task.
2. Fashion MNIST
This dataset is a bit similar to MNIST, all images are in 28x28 grayscale and tagged with a label from 10 classes, but the topics are fashion-related which includes T-shirt/top, trousers, pullover, dress, coat, sandal, shirt, sneaker, bag and ankle boot. This data is provided by the research team of Zalando, a fashion retailer.
3. The CIFAR-10 dataset & 4. The CIFAR-100 dataset
Both CIFAR-10 and CIFAR-100 are prepared by the Canadian Institute For Advanced Research. CIFAR-10 consists of 60thousands of images in 10 classes which are airplane, automobile, bird, cat, deer, dog, frog, horse, ship and truck. CIFAR-100 is similar, there are also 60thousands of images in total but there are 100 classes, and so 600 images per each class. The two datasets are user-friendly for beginners as they are all formatted in 32x32 pixels and pre-split into a training set of 50thousands of images and a test set of 10thousands of images with an equal proportion of data from all classes.
5. IMDB-Wiki Dataset
This dataset contains 520thousands of face images scraped from IMBD and Wikipedia. The data come along with some important meta information like the face location in the image, the name, the date of birth and the gender of the person in photos. This dataset is typically used for gender prediction and age prediction tasks.
6. ImageNet
This dataset was created jointly by Standford University and Princeton University for a typical computer vision competition called The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) where participating teams were challenged with 5 main tasks, i.e. object classification, object localisation, object detection, object detection from video and scene recognition using the ImageNet dataset. This dataset is built base on the WordNet (A lexical database for English) hierarchy where only nouns are selected. There are on average over 500 images per each node of the hierarchy. Altogether there are more than 1.4millions of images of over 220thousands of classes. It is so far the largest classified image dataset available and open to the public.
7. The Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes dataset (PASCAL VOC Dataset, in short)
This dataset was open-sourced by PASCAL, a research institute funded by the European Union. There are images from 4 main topics including vehicle, household, animal and person. The data are further divided into 20 subcategories. Although the data volume and class varieties are not as much as ImageNet, PASCAL VOC Dataset is more widely used in the early development of object detection and image segmentation.
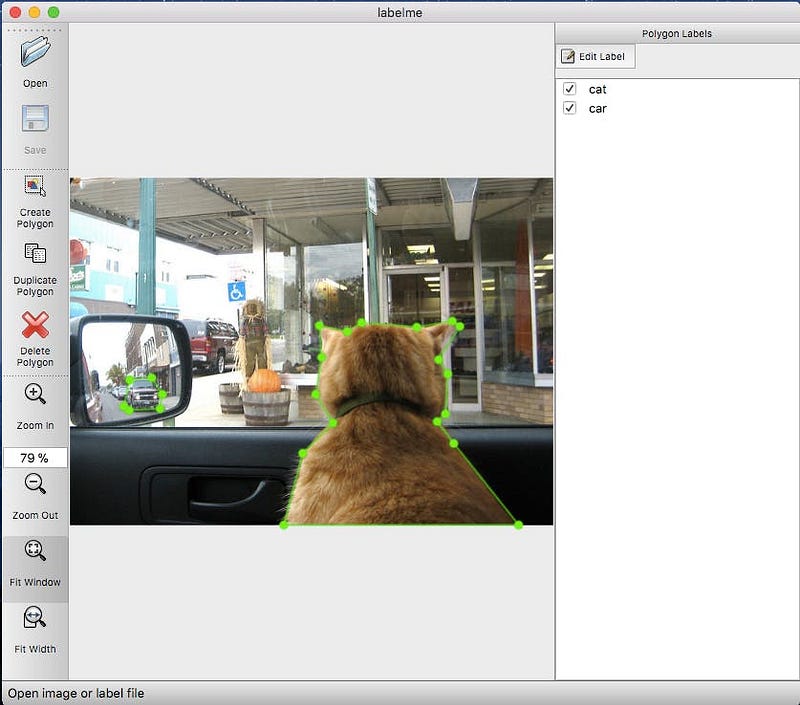
8. LabelMe Dataset
The dataset is built by using LabelMe, an open annotation tool which allows users to outline an object and add an annotation text to that object. The tool is maintained by MIT with a goal to build image databases for computer vision research. This dataset is generally used for image segmentation.
9. Microsoft Common Objects in Context Dataset (MS COCO Dataset, in short)
This dataset is published by Microsoft for the Common Objects in Context Challenge which includes object detection, segmentation, person keypoints detection, stuff segmentation, and caption generation. There are over 120thousands of images with over 880thousands tags (multiple tags are allowed in each image) in this dataset. In all, there are 91 categories. Even though both the total number of images and the number of categories is fewer than ImageNet, the number of image per each category is at least 5000 which allows the machine to learn the detailed characteristics of each class.
10. Places2 Database
Places2 is another dataset released by MIT, it has more than 10 million images and over 400 scenes. It has been used as the dataset of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC 2015 and ILSVRC 2016) for the task of scene classification and scene parsing.










Comments
Post a Comment